今天我們來介紹如何在表格中:
GT.tab_spanner())。GT.tab_stub())GT.tab_stubhead())。以下將繼續使用df_demo為範例說明:
GT.tab_spanner()GT.tab_spanner(self, label, columns=None, spanners=None, level=None, id=None, gather=True, replace=False)
GT.tab_spanner()可以讓使用者針對選取的欄位建立階層。例如:
(GT(df_demo).tab_spanner(label="floats", columns=["float1", "float2"]))
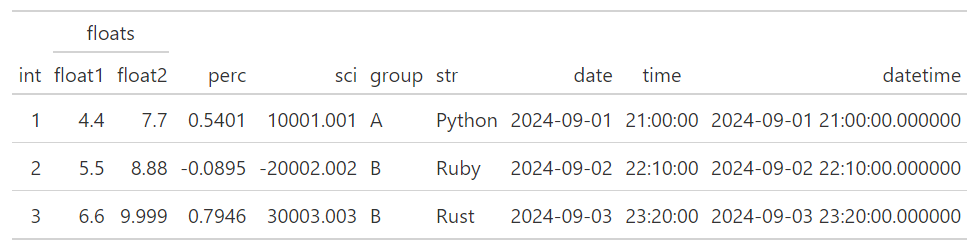
我們可以透過多次呼叫GT.tab_spanner()建立多個階層。例如:
(
GT(df_demo)
.tab_spanner(label="ints", columns=["int"])
.tab_spanner(label="floats", columns=["float1", "float2"])
)
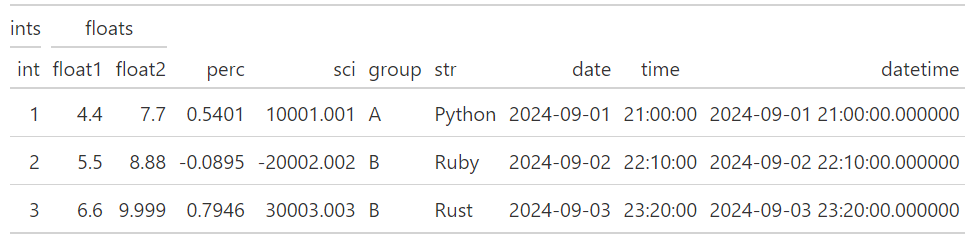
此外,也可以建立多層次的階層。例如:
(
GT(df_demo)
.tab_spanner(label="ints", columns=["int"])
.tab_spanner(label="floats", columns=["float1", "float2"])
.tab_spanner(label="numbers", columns=["int", "float1", "float2"])
)
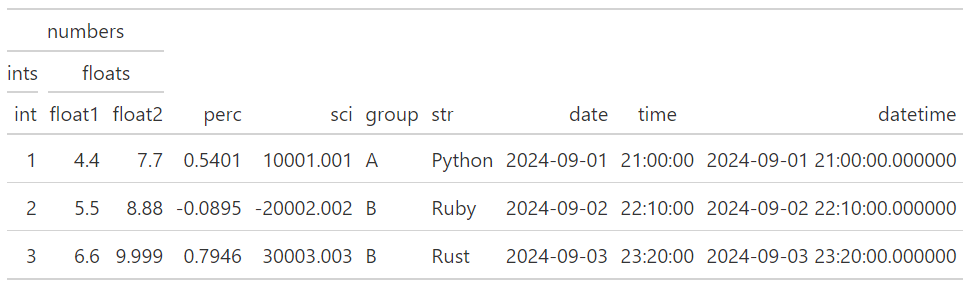
有趣的是,使用者可以透過level參數來控制其所處的階層位置。例如:
(
GT(df_demo)
.tab_spanner(label="ints", columns=["int"])
.tab_spanner(label="floats", columns=["float1", "float2"])
.tab_spanner(
label="numbers", columns=["int", "float1", "float2"], level=0
)
)
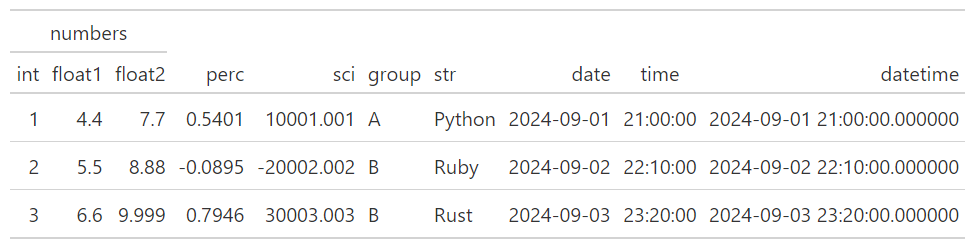
如果不指定level的話,gt會自動判斷各階層最合理的位置。而level=0則代表將該階層指定為最靠近欄位名稱的一層。
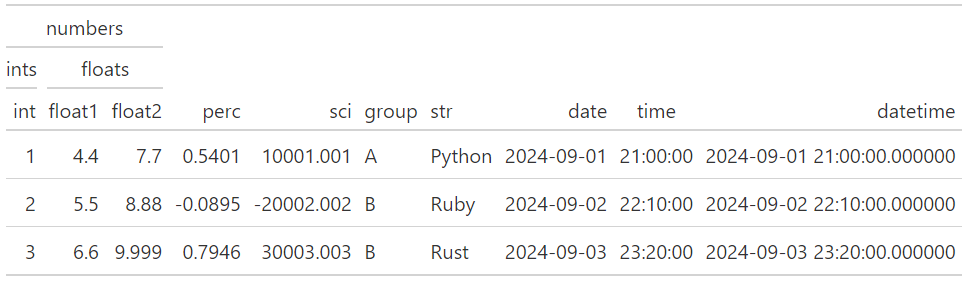
最後,別忘了在gt中選擇欄位的方法十分多元。下面這個範例使用了索引值、Polars expression及混用欄位名稱與Polars expression等三種選取方式:
float_cols = cs.starts_with("float")
(
GT(df_demo)
.tab_spanner(label="ints", columns=0)
.tab_spanner(label="floats", columns=float_cols)
.tab_spanner(label="numbers", columns=["int", float_cols])
)
GT.tab_stub()GT.tab_stub(self, rowname_col=None, groupname_col=None)
GT.tab_stub()可以讓使用者針對所選取的一個或兩個欄位名進行分類。
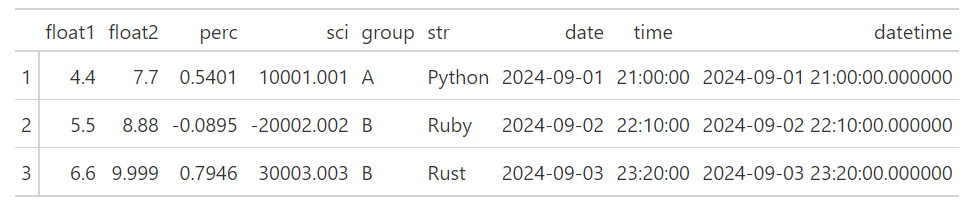
如果只有選取一個欄位,其必須指定為rowname_col。例如:
(GT(df_demo).tab_stub(rowname_col="int"))
如果只有選取一個欄位,卻指定為groupname_col時,會出現下面這個gt無法判斷的情況:
(GT(df_demo).tab_stub(groupname_col="group"))
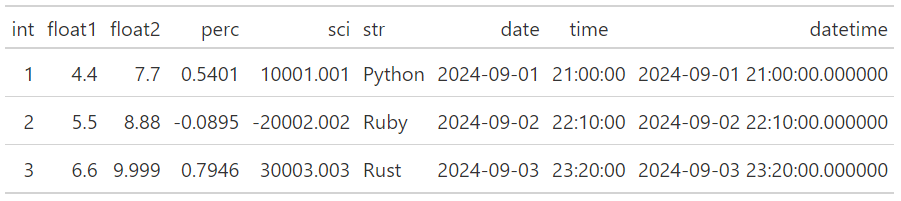
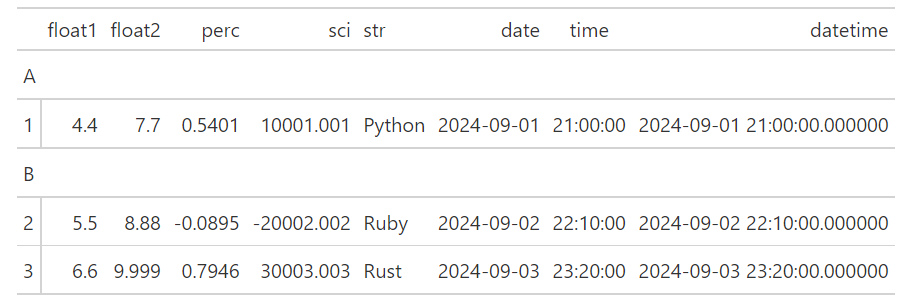
如果選取兩個欄位,分別作為rowname_col及groupname_col,則可呈現分類的效果:
(GT(df_demo).tab_stub(groupname_col="group", rowname_col="int"))
由於GT.tab_stub()是比較新的功能,在一些legacy code中,您可能會見到下面這種用法:
GT(df_demo, groupname_col="group", rowname_col="int")
雖然這樣的使用方法仍被接受,但卻比較沒有彈性。因為這麼一來,groupname_col及rowname_col需要於生成GT時決定,而不是透過GT.tab_stub()這樣的fluent API添加上去。
GT.tab_stubhead()GT.tab_stubhead(self, label)
GT.tab_stubhead()可以指定Stub head呈現的內容。例如:
(GT(df_demo).tab_stub(rowname_col="int").tab_stubhead("Stubhead"))


